
La integración masiva de las tecnologías de la información, bajo diferentes aspectos del mundo moderno, ha llevado al tratamiento de los vehículos como recursos conceptuales en los sistemas de información. Dado que un sistema de información autónomo no tiene sentido sin datos, es necesario reformar la información del vehículo entre la realidad y el sistema de información, lo que puede conseguirse mediante agentes humanos o mediante equipos inteligentes especiales que permitan la identificación de los vehículos por sus placas de matrícula en entornos reales.
El sistema de detección y reconocimiento de matrículas de vehículos se utiliza para detectarlas y luego hacer el reconocimiento de la misma extrayendo el texto de una imagen y todo ello gracias a los módulos de cálculo que utilizan algoritmos de localización, segmentación de matrículas y reconocimiento de caracteres. La detección y lectura de matrículas es una especie de sistema inteligente y es considerable debido a las aplicaciones potenciales en varios sectores que se citan a continuación:
- vehículos robados y registrados. Las placas detectadas se comparan con las de los vehículos notificados.
- Gestión de aparcamientos: La gestión de las entradas y salidas de vehículos.
- entrada y salida de automoviles en barrios cerrados o countrys.
- Seguridad vial: Este sistema se utiliza para detectar matrículas de coches que superan una velocidad determinada, acoplar el sistema de lectura de matrículas con un radar de carretera.
Paso1 : Detección de matrículas
Para detectar la licencia utilizaremos la arquitectura de detección de objetos de aprendizaje profundo Yolo («You Only Look One») basada en «convolution neural networks».
Esta arquitectura fue introducida por Joseph Redmon, Ali Farhadi, Ross Girshick y Santosh Divvala en su primera versión en 2015 y posteriormente en las versiones 2 y 3.
Yolo es una red para realizar una tarea de regresión que predice tanto la caja de límites de objeto como la clase de objeto.
Esta red es extremadamente rápida, procesa imágenes en tiempo real a 45 fotogramas por segundo. Una versión más pequeña de la red, Fast YOLO, procesa 155 imágenes por segundo.
Implementación de YOLO V3:
En primer lugar, hemos preparado un conjunto de datos compuesto por 700 imágenes de coches que contiene la matrícula tunecina, para cada imagen, hacemos un archivo xml (Cambiado después a un archivo de texto que contiene coordenadas compatibles con la entrada del archivo de configuración de Darknet. Darknet : proyecto utilizado para reciclar los modelos preentrenados de YOLO) usando una aplicación de escritorio llamada LabelImg.
# First download Darknet project $ git clone https://github.com/pjreddie/darknet.git # in "darknet/Makefile" put affect 1 to OpenCV, CUDNN and GPU if you # want to train with you GPU then time thos two commands $ cd darknet $ make # Load convert.py to change labels (xml files) into the #appropriate # format that darknet understand and past it under darknet/ #https://github.com/KhazriAchraf/ANPR# Unzip the dataset $ unzip dataset.zip # Create two folders, one for the images and the other for labels $ mkdir darknet/images $ mkdir darknet/labels # Convert labels format and create files with location of images # for the test and the training $ python convert.py # Create a folder under darknet/ that will contain your data $ mkdir darknet/custom # Move files train.txt and test.txt that contains data path to # custom folder $ mv train.txt custom/ $ mv test.txt custom/ # Create file to put licence plate class name "LP" $ touch darknet/custom/classes.names $ echo LP > classes.names # Create Backup folder to save weights $ mkdir custom/weights # Create a file contains information about data and cfg # files locations $ touch darknet/custom/darknet.data # in darknet/custom/darknet.data file paste those informations classes = 1 train = custom/train.txt valid = custom/test.txt names = custom/classes.names backup = custom/weights/ # Copy and paste yolo config file in "darknet/custom" $ cp darknet/cfg/yolov3.cfg darknet/custom# Open yolov3.cfg and change : # " filters=(classes + 5)*3" just the ones before "Yolo" # in our case classes=1, so filters=18 # change classes=... to classes=1# Download pretrained model $ wget https://pjreddie.com/media/files/darknet53.conv.74 -O ~/darknet/darknet53.conv.74# Let's train our model !!!!!!!!!!!!!!!!!!!!! $ ./darknet detector train custom/darknet.data custom/yolov3.cfg darknet53.conv.74
Después de terminar el entrenamiento, para detectar una placa de matrícula de una imagen, elija el último modelo de darknet/custom/weights , y ponga su ruta o nombre en el archivo object_detection_yolo.py, también usaremos el archivo yolov3.cfg, justo en este archivo put # antes de entrenar para que podamos entrenar y luego ejecutar :
python object-detection_yolo.py --image= image.jpg
y esto es lo que tenemos como resultado:

Paso 2: Segmentación de las matrículas
Ahora tenemos que segmentar nuestro número de matrícula. La entrada es la imagen de la placa, tendremos que poder extraer las imágenes de ella. El resultado de este paso, que se utiliza como entrada a la fase de reconocimiento, es de gran importancia
La segmentación es uno de los procesos más importantes para la identificación automática de matrículas, ya que cualquier otro paso se basa en ella. Si la segmentación fracasa, la fase de reconocimiento no será correcta, por lo que para asegurar una segmentación adecuada, se tendrá que realizar un procesamiento preliminar.
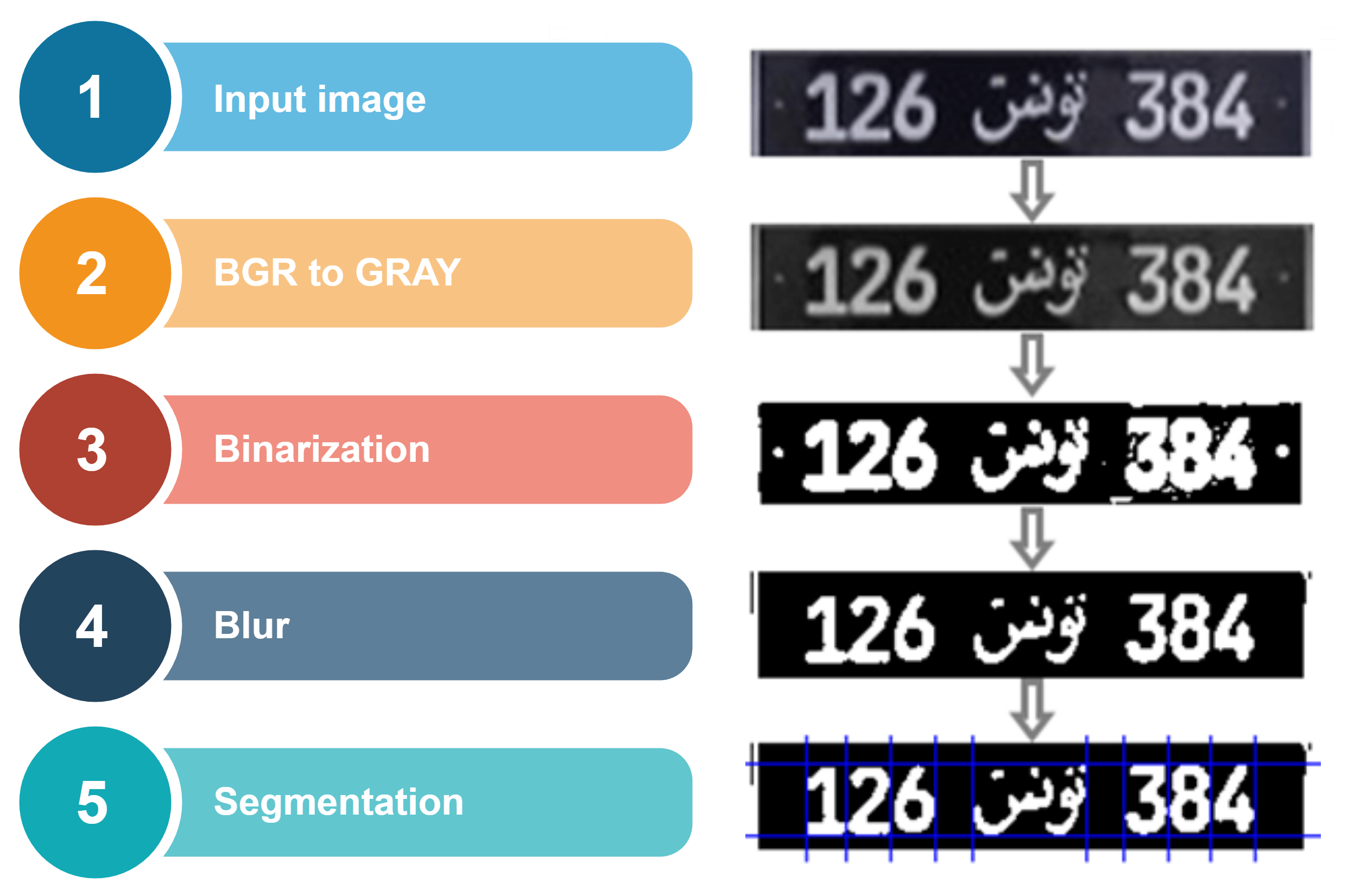 El histograma de proyección de píxeles consiste en encontrar los límites superior e inferior, izquierdo y derecho de cada carácter. Realizamos una proyección horizontal para encontrar las posiciones superior e inferior de los caracteres. El valor de un grupo de histogramas es la suma de los píxeles blancos a lo largo de una línea particular en la dirección horizontal.
El histograma de proyección de píxeles consiste en encontrar los límites superior e inferior, izquierdo y derecho de cada carácter. Realizamos una proyección horizontal para encontrar las posiciones superior e inferior de los caracteres. El valor de un grupo de histogramas es la suma de los píxeles blancos a lo largo de una línea particular en la dirección horizontal.
Cuando se calculan todos los valores a lo largo de todas las líneas en la dirección horizontal, se obtiene el histograma de proyección horizontal. El valor medio del histograma se utiliza como umbral para determinar los límites superior e inferior. El área central cuyo segmento del histograma es mayor que el umbral se registra como el área delimitada por los límites superior e inferior. Entonces de la misma manera calculamos el histograma de proyección vertical pero cambiando las filas por las columnas de la imagen para tener los dos límites de cada carácter (izquierda y derecha).
![]() Otro método para extraer dígitos de la matrícula es usar morfología de abrir/cerrar para hacer algún tipo de región conectada y luego usar algoritmos de componentes conectados para extraer regiones conectadas.
Otro método para extraer dígitos de la matrícula es usar morfología de abrir/cerrar para hacer algún tipo de región conectada y luego usar algoritmos de componentes conectados para extraer regiones conectadas.
Paso 3: Reconocimiento de matrículas
La fase de reconocimiento es el último paso en el desarrollo del sistema de lectura automática de matrículas. Así, se cierran todos los procesos pasando por la adquisición de la imagen, seguida de la localización de la placa hasta la segmentación. El reconocimiento debe hacer de las imágenes caracteres obtenidos al final de la fase de segmentación. El modelo de aprendizaje que se utilizará para este reconocimiento debe ser capaz de leer una imagen y representar el carácter correspondiente.
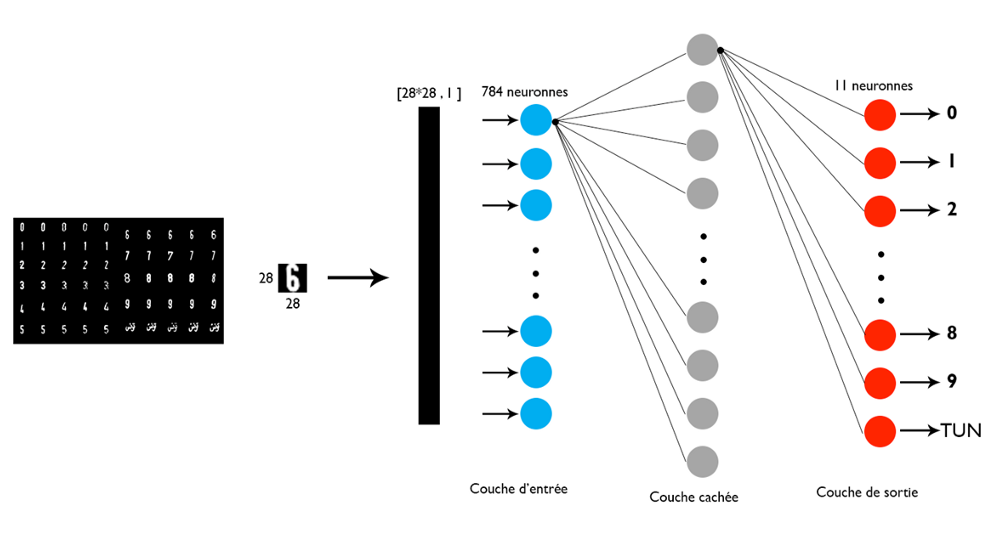
Para aprovechar al máximo los datos disponibles para el aprendizaje, cortamos cada carácter individualmente redimensionándolo en un cuadrado después de aplicar los mismos pasos de procesamiento de imagen utilizados antes de la segmentación de la matrícula. Como resultado, obtuvimos un conjunto de datos compuesto por 11 clases y para cada clase tenemos 30-40 imágenes de 28X28 píxeles en formato PNG; números del 0 al 9 y la palabra en árabe (Túnez).
A continuación, realizamos algunas investigaciones basadas en artículos científicos que comparan el perceptrón multicapa (MLP) y el clasificador K con los vecinos más cercanos (KNN). Y como resultado hemos encontrado que: el rendimiento aumenta si el número de neuronas de la capa oculta también aumenta cuando se usa el clasificador MLP y si el número del vecino más cercano también aumenta cuando se usa el KNN. la capacidad de ajustar el rendimiento del clasificador k-NN es muy limitada aquí. Pero un número ajustable de capas ocultas y pesos de conexión MLP ajustables proporciona una mayor oportunidad para refinar las regiones de decisión. Como resultado, elegiremos el perceptrón multicapa para esta fase.
 Encontrarás todo el código y los conjuntos de datos en los siguientes links:
Encontrarás todo el código y los conjuntos de datos en los siguientes links:
https://github.com/KhazriAchraf/ANPR
https://www.kaggle.com/achrafkhazri/anpr-dataset-tunisian-plates-and-digits










