
REACT SEO | Google definitivamente es el buscador mas usado en internet y recibe un gran porcentaje de las solicitudes de búsquedas a nivel mundial. Y los primeros 10 enlaces que aparecen en los resultados de búsqueda (SERPS )son los que más tráfico reciben, en realidad la mayoría hace click en los 3 primeros resultados de búsqueda. Así de vital es la optimización del motor de búsqueda en términos del éxito para una aplicación o desarrollo web.
Para muchas empresas la optimización de sus desarrollos pensadas para los motores de búsqueda es fundamental y optar por REACT para hacer aplicaciones web interactivas y dinámicas suele traer algunas preocupaciones relacionadas con su facilidad o no con respecto al SEO.
La idea es descubrir si es confiable React a la hora de crear un producto de software compatible con el SEO. Es necesario conocer los principales obstáculos que impiden que React sea compatible con el SEO y entender cuales son las mejores prácticas para hacer que nuestra aplicación web sea atractiva para Google.
Para entender y resolver el problema de las aplicaciones web creadas con React con el SEO, debemos comprender cómo funcionan los robots de Google y a qué problemas comunes se enfrentan las soluciones de React.
Contenidos
Descripción general de los Bots rastreadores de Google (user-agents)
El término «rastreador» se utiliza de forma genérica para hacer referencia a cualquier programa (como un robot o una araña) que sirve para detectar y analizar automáticamente sitios web siguiendo enlaces entre páginas web.
El proceso de rastreo comienza con una lista de direcciones web de rastreos anteriores y mapas de sitios web proporcionados por los propietarios de los sitios web. Los Bots rastreadores visitan estos sitios web, utilizan los enlaces de estos sitios para descubrir otras páginas. El software presta especial atención a los sitios nuevos, a los cambios en los sitios existentes y a los enlaces muertos. Los algoritmos de Google determinan qué sitios rastrear, con qué frecuencia y cuántas páginas buscar en cada sitio.
Generalmente hay dos tipos de crawlers:
- Los de buscadores: Google, Bing, Yandex, Baidu, etc.
- Los de herramientas SEO como Screaming Frog, Ahrefs, Semrush, etc.
Lo que al final hace Google es leer todo lo que hay en Internet y mostrar los resultados más relevantes para el usuario cuando este busca cualquier cosa.
Para esto hace uso de unos programas que tienen varios nombres: robots, crawlers, rastreadores o bots. Aunque el que más usado es el de arañas por la imagen metafórica de tejer Internet en base a descubrir webs siguiendo los enlaces entre ellas.
Los principales crawlers que usa Google son los siguientes:
- Googlebot: crawler para analizar una web desde el punto de vista de un usuario con ordenador de escritorio o desktop.
- Smartphone Googlebot: este bot hace el crawling como si se trata de un dispositivo móvil.
Pero tiene más crawlers: uno para imágenes, otro para notícias, varios relacionados con los anuncios, etc.
Desde 2019, Google está potenciando el Googlebot Smartphone siguiendo la tendencia de que cada vez más visitamos la red desde nuestros teléfonos móviles.
¿Cómo funciona Google a nivel técnico?
No sé si alguna vez te has planteado cómo funciona Google a nivel técnico, es decir, qué ocurre desde que tú lanzas un dominio o una página nueva a Internet hasta que aparece en el buscador.
- Paso 1: Lanzas tu nueva página (o tu nuevo proyecto) a Internet.
- Paso 2: Los servidores de Google reciben un ping de ese nuevo contenido.
Es algo que, por ejemplo, WordPress hace de forma automática y se basa a nivel programación en decirle a Google: Oye, acabo de publicar algo que no tienes, ¡pásate cuando puedas y lo ves! - Paso 3: Google lanza un crawler hacia el contenido nuevo.
- Paso 4: Ese crawler llega al contenido nuevo y leerá la nueva página web o dominio, siguiendo sus enlaces, normalmente hasta un tercer nivel pero, esta parte es accesoria en estos momentos. Lo importante es que este crawler leerá el código de tu página web, no tu diseño. Si quieres saber cómo ve un crawler una página, prueba a darle al botón derecho del ratón y “Ver cómo código fuente”. Eso es lo que analiza el rastreador.
- Paso 5: El crawler va leyendo información y, una vez ha terminado, la comprime y se la lleva al servidor de Google.
- Paso 6: Esta información se indexa en el servidor de Google, a la espera de que el buscador le otorgue una relevancia para las palabras clave que sea relevante.
- Paso 7: Un usuario realiza una búsqueda en Google.
- Paso 8: Google se va a por las páginas que son más relevantes para esa búsqueda y usuario en concreto.
- Paso 9: Google lista todos los resultados del más relevante al menos relevante.
- Paso 10: El usuario pincha en uno de ellos y entra a ver el contenido.
Si has leído todos los pasos del primero al último habrás comprobado que, sin la presencia de un crawler, sencillamente Google no funcionaría y, por eso, son tan importantes.
Problemas comunes de indexación con páginas renderizadas con JavaScript
Estos son los problemas más comunes con las páginas de JavaScript que pueden influir en su indexación y los resultados de posicionamiento.
Proceso de indexación lento y complejo
Los robots de Google pueden escanear y entender fácilmente sólo las páginas HTML.
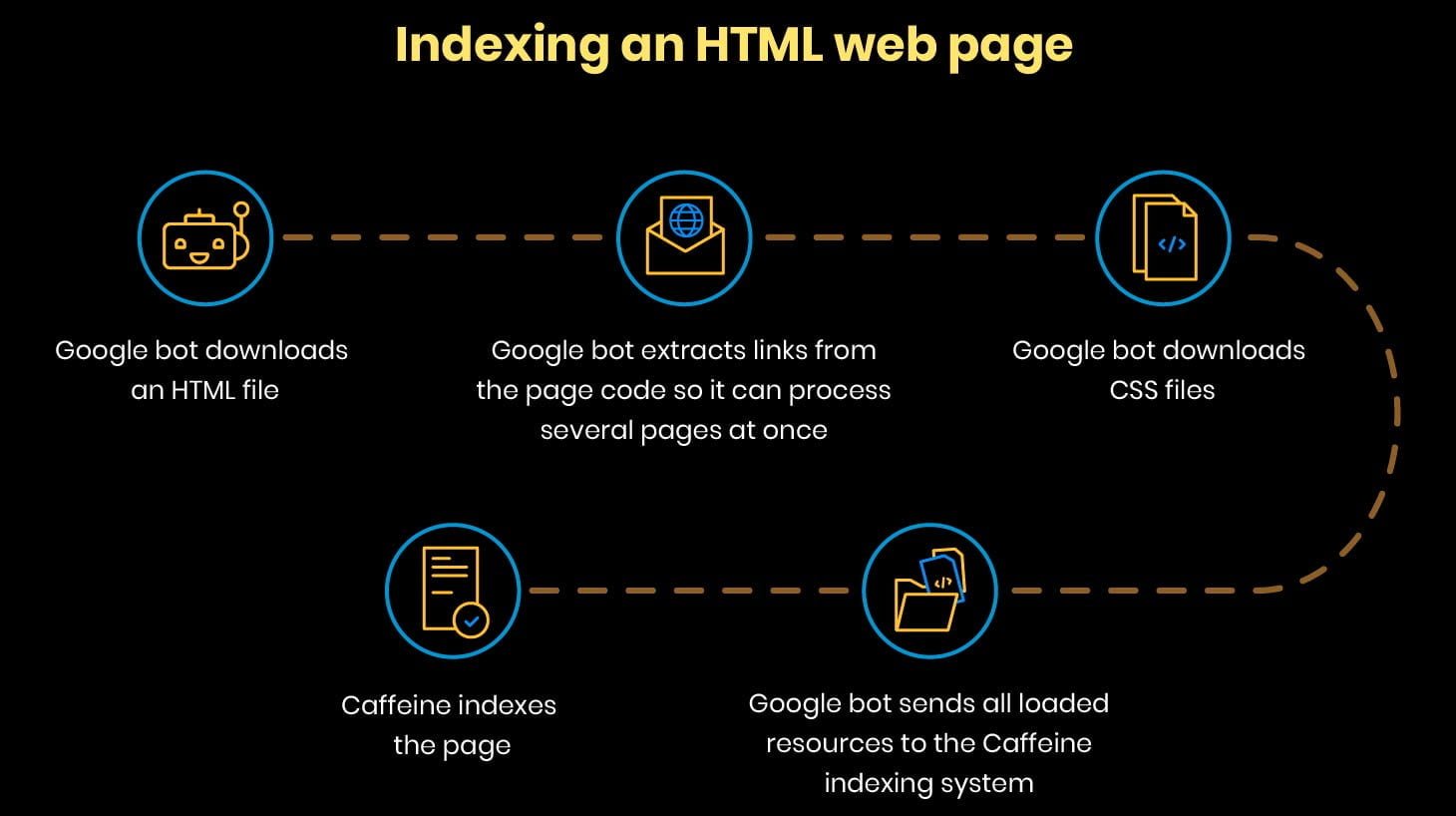 Google realiza todas estas operaciones muy rápidamente. Pero cuando se trata de páginas con código JavaScript, el proceso de indexación se vuelve más complejo.
Google realiza todas estas operaciones muy rápidamente. Pero cuando se trata de páginas con código JavaScript, el proceso de indexación se vuelve más complejo.
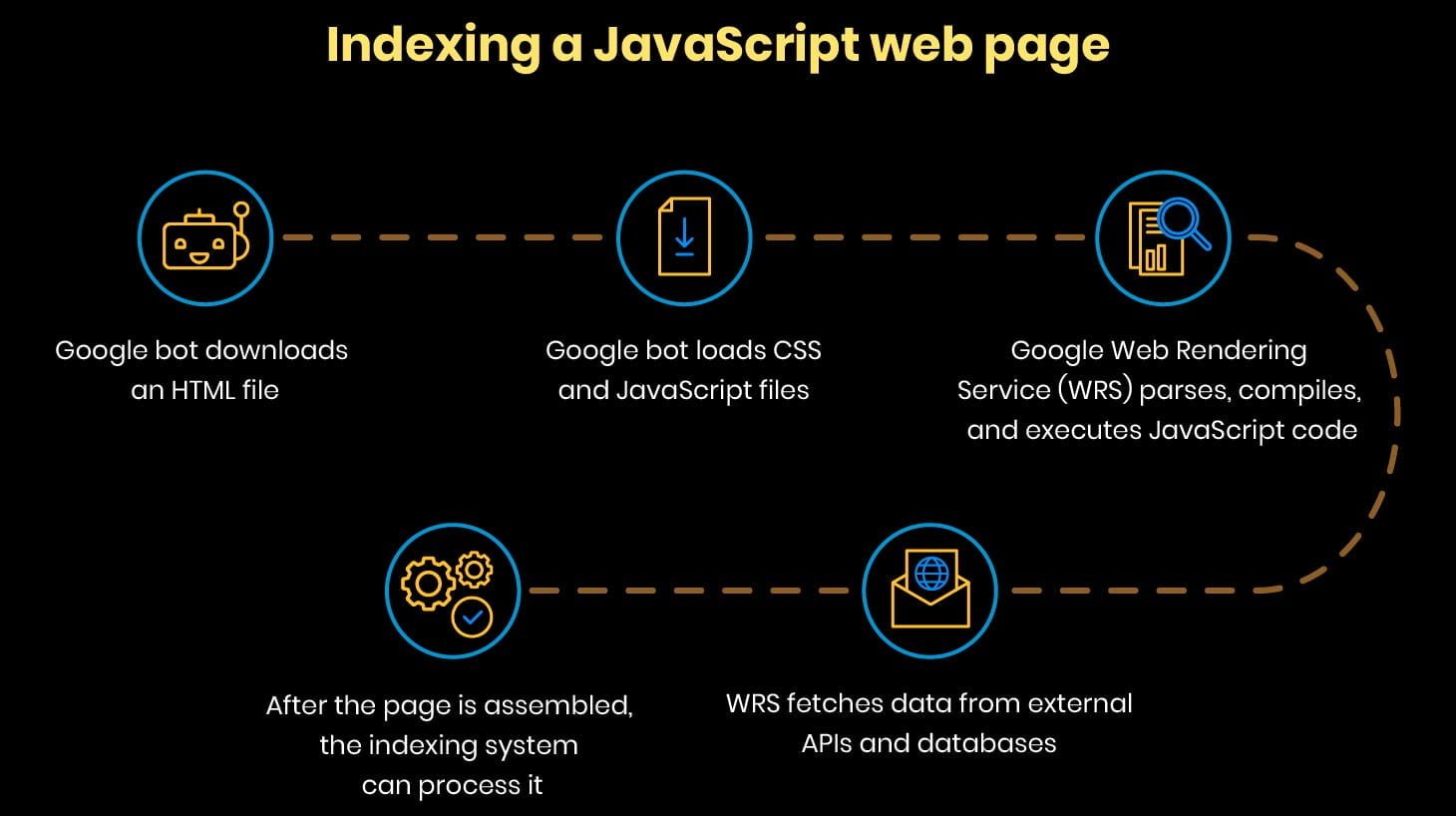 Sólo cuando todos estos pasos se cumplen, el robot puede encontrar nuevos enlaces y añadirlos a la cola de rastreo.
Sólo cuando todos estos pasos se cumplen, el robot puede encontrar nuevos enlaces y añadirlos a la cola de rastreo.
Este proceso es lineal y significativamente más lento que la indexación de una página HTML.
Errores el código de Javascript
El HTML y el JavaScript tienen enfoques absolutamente diferentes para procesar los errores. Un solo error en el código JavaScript puede hacer imposible la indexación.
Esto se debe a que el analizador o parser de JavaScript es completamente intolerante a los errores. Si se encuentra con un caracter raro en un lugar inesperado, inmediatamente deja de analizar el script actual y muestra un SyntaxError. Por lo tanto, un solo carácter o error tipográfico puede llevar a la completa inoperabilidad del script. Si esta situación se produce cuando el bot de Google está indexando la página, el bot verá una página vacía y la indexará como una página sin contenido.
Un crawling budget muy alto
Un Crawling Budget es el número máximo de páginas que los robots de los motores de búsqueda pueden rastrear en un período de tiempo específico (normalmente cinco segundos para un script).
Muchos sitios web construidos en JavaScript experimentan problemas de indexación porque Google tiene que esperar demasiado tiempo (más de cinco segundos) para que las secuencias de comandos se carguen, analicen y ejecuten. Las secuencias de comandos lentas significan que el bot de Google se quedará rápidamente sin su presupuesto o Budget de rastreo para el sitio y lo abandonará antes de indexarlo (un bajón).
Desafíos de la indexación de las SPA’s
Las aplicaciones de una sola página (SPA) son aplicaciones web creadas con React. Estas aplicaciones web consisten en una sola página que se carga una vez. El resto de la información se carga dinámicamente cuando es necesario. A diferencia de las aplicaciones tradicionales de varias páginas, las SPA son rápidas, responden y proporcionan a los usuarios una experiencia lineal sin problemas.
Sin embargo, a pesar de todos estos beneficios para los usuarios finales, las SPA tienen una limitación significativa en términos de SEO. Estas aplicaciones web pueden dar contenido cuando la página ya está cargada. Si un robot está rastreando la página cuando el contenido no se ha cargado, el robot verá una página vacía. Una parte significativa del sitio no será indexada. Por lo tanto, el sitio obtendrá una clasificación mucho más baja en los resultados de búsqueda.
Cómo hacer que tu sitio realizado React sea SEO-friendly
Todas las limitaciones que vimos anteriormente pueden ser evitadas. Aquí están las mejores prácticas que puedes usar para resolver los problemas de React y SEO.
Pre-rendering
El pre-renderizado es un enfoque común para hacer que las aplicaciones web de una o varias páginas sean compatibles con el SEO.
La pre-renderización se utiliza cuando los robots de búsqueda no pueden renderizar sus páginas correctamente. En estos casos, puede utilizar pre-renders: programas especiales que interceptan las solicitudes a tu sitio web y, si la solicitud es de un robot, los pre-renders envían una versión HTML estática en caché de tu sitio web. Si la solicitud es de un usuario, se carga la página habitual.
Ventajas del Pre-Rendering
- Los programas de pre-renderización son capaces de ejecutar todo tipo de Javascript moderno y transformarlo en HTML estático.
- Este enfoque requiere mínimas modificaciones de código o casi ninguna modificación en absoluto.
- Es simple de implementar.
Inconvenientes en este enfoque
- No es adecuado para páginas que muestran datos que cambian frecuentemente.
- La pre-renderización puede tomar demasiado tiempo si el sitio web es grande y contiene muchas páginas.
- Los servicios de pre-rendering no son gratuitos.
- Necesitas reconstruir tu página pre-renderizada cada vez que cambies tu contenido.
Server-side rendering (Renderización del lado del servidor)
Si hablamos de React, necesitas saber la diferencia entre el renderizado del lado del cliente y del lado del servidor.
El renderizado del lado del cliente significa que un navegador y un robot de Google obtienen archivos HTML vacíos o con poco contenido. Luego el código JavaScript descarga el contenido del servidor y los usuarios lo ven en sus pantallas.
En términos de SEO, la renderización del lado del cliente es un problema, ya que los robots de Google no obtienen ningún contenido u obtienen muy poco de contenido que no pueden indexar correctamente.
Con el renderizado del lado del servidor, los navegadores y los robots de Google obtienen archivos HTML con todo el contenido. Los robots de Google pueden indexar la página correctamente y clasificarla en una posición más alta.
La renderización del lado del servidor es la forma más fácil de crear un sitio web de React que sea compatible con el SEO.
Next.js
Next.js es una herramienta poderosa para resolver los problemas de SEO de las aplicaciones de una sola página.
Next.js es un framework que llega para ayudarnos con la creación de páginas dinámicas del lado del servidor y que nos ofrece una solución muy potente para trabajar con React.
Es una herramienta que nos ayuda en la misión de realizar el “render-side rendering”, es decir, el renderizado de las páginas o pantallas de la aplicación directamente en el servidor. De esta manera, el “peso” del procesamiento y creación de páginas lo volcamos principalmente al lado servidor. Esta técnica también resulta adecuada cuando pensamos en el posicionamiento en los buscadores (SEO), ya que posee un muy eficiente manejo de rutas para las URLs que conformen nuestro proyecto.










