
La fabricación o trucado de fotos porno de celebridades no es nada nuevo. Sin embargo, a finales de 2017, un usuario de Reddit llamado Deepfakes comenzó a aplicar Deep Learning para crear estos famosos videos falsos de celebridades. Eso inicia una nueva ola de videos falsos en línea. DARPA, como parte del ejército estadounidense, también está financiando la investigación para detectar videos falsos. En realidad, la aplicación de la IA para crear vídeos comenzó mucho antes que Deepfakes. Face2Face y UW’s «synthesizing Obama (learning lip sync from audio)» crean videos falsos que son aún más difíciles de detectar.
En este artículo, la idea es explicar el concepto de Deepfakes y explicamos formas de identificar videos falsos.
Contenidos
Conceptos básicos sobre Deepfake
El concepto de Deepfakes es muy simple. Digamos que queremos transferir la cara de la persona A a un video de la persona B.
En primer lugar, recogemos cientos o miles de fotos para ambas personas. Construimos un codificador para todas estas imágenes utilizando deep learning CNN network. Luego usamos un decodificador para reconstruir la imagen. Este autoencoder (el codificador y el decodificador) tiene más de un millón de parámetros pero no está lo suficientemente cerca para recordar todas las imágenes. Por lo tanto, el codificador necesita extraer las características más importantes para recrear la entrada original. deberiamos pensar en un bosquejo criminal o retrato hablado para identificar a un delincuente. Las características son las descripciones de un testigo (codificador) y un dibujante compuesto (decodificador) las utiliza para reconstruir una imagen del sospechoso.
Para decodificar las características, se usan decodificadores separados para la persona A y la persona B. Ahora, se entrena el codificador y los decodificadores (usando la retropropagación o backpropagation) de tal manera que la entrada coincida estrechamente con la salida. Este proceso lleva mucho tiempo. Con una tarjeta gráfica de GPU, se tarda unos 3 días en generar resultados decentes. (después de repetir el procesamiento de imágenes durante más de 10 millones de veces).
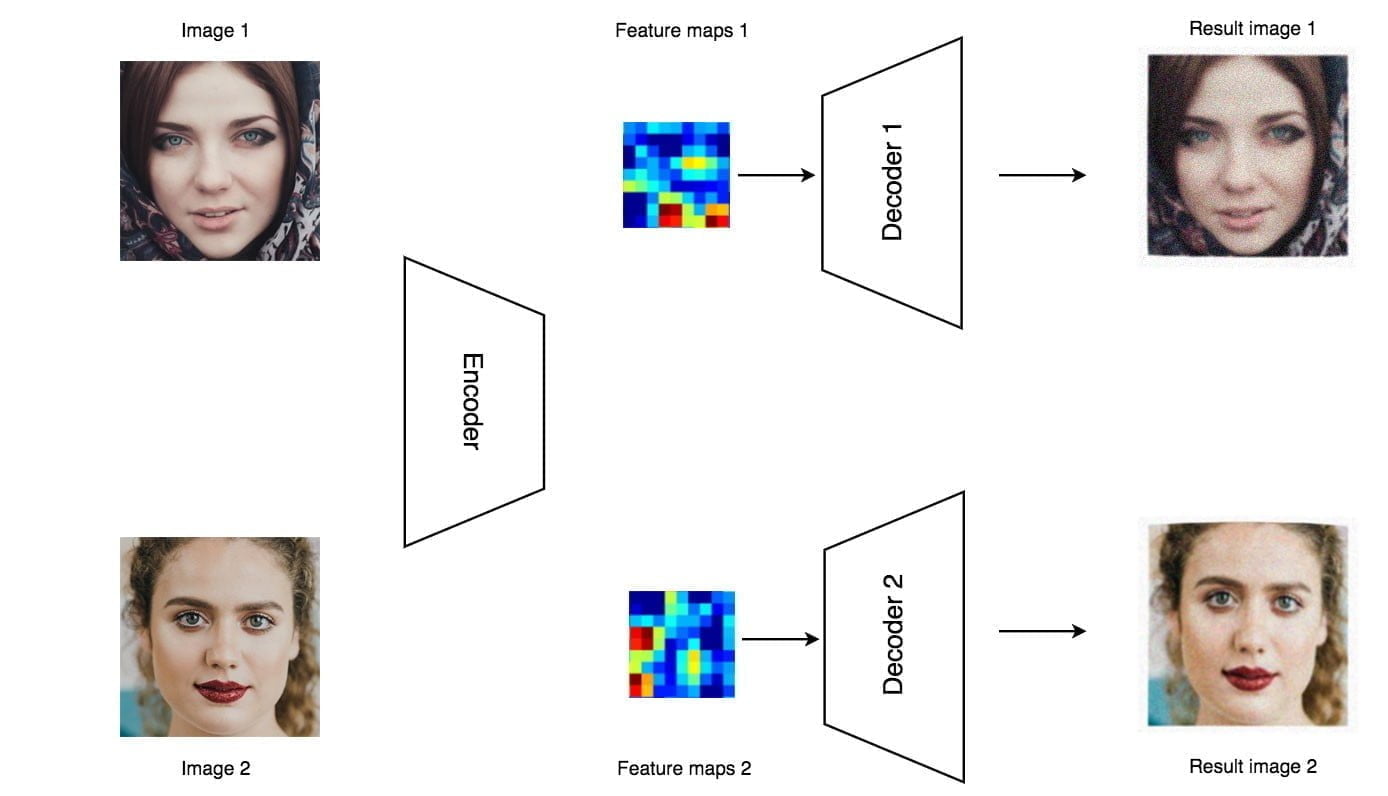
Después del entrenamiento, se procesa el video fotograma por fotograma para intercambiar la cara de una persona con la de otra. Mediante la detección de rostros, extraemos la cara de la persona A y la introducimos en el codificador. Sin embargo, en lugar de alimentar su decodificador original, usamos el decodificador de la persona B para reconstruir la imagen, es decir, dibujamos a la persona B con las características de A en el vídeo original. Luego fusionamos la cara recién creada con la imagen original.
 Intuitivamente, el codificador detecta el ángulo de la cara, el tono de la piel, la expresión facial, la iluminación y toda información que sea importante para reconstruir a la persona A. Cuando usamos el segundo decodificador para reconstruir la imagen, estamos dibujando a la persona B pero con el contexto de A. En la imagen de abajo, la imagen reconstruida tiene caracteres faciales de Trump mientras que mantiene la expresión facial del vídeo de destino.
Intuitivamente, el codificador detecta el ángulo de la cara, el tono de la piel, la expresión facial, la iluminación y toda información que sea importante para reconstruir a la persona A. Cuando usamos el segundo decodificador para reconstruir la imagen, estamos dibujando a la persona B pero con el contexto de A. En la imagen de abajo, la imagen reconstruida tiene caracteres faciales de Trump mientras que mantiene la expresión facial del vídeo de destino.

Cuestiones de Imagen

Antes del entrenamiento, necesitamos preparar miles de imágenes para ambas personas. Podemos tomar un atajo y usar una biblioteca de detección de rostros para hacer scrapping de las fotos faciales de sus videos. Es necesario tomarse un tiempo considerable a mejorar la calidad de las fotografías faciales. Impacta significativamente el resultado final.
- Quite los marcos de fotos que contengan más de una persona.
- Deberiamos tener mucho material en video. Las fotografías faciales extraídas de estos videos contienen diferentes posturas, ángulos y expresiones faciales.
- Elimine cualquier fotografía facial de mala calidad, teñida, pequeña, con mala iluminación.
- Algunos imagenes que se parezcan a ambas personas pueden ayudar, como la forma similar de la cara.
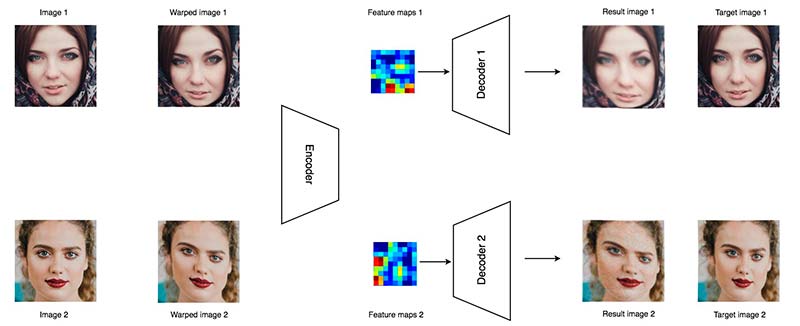
No queremos que nuestro autoencoder simplemente recuerde la entrada de entrenamiento y replique la salida directamente. Tenemos que saber que todas las posibilidades no son factibles. Introducimos el denoising para introducir variantes de datos y entrenar un autoencoder para aprender inteligentemente. El término «denoising» puede ser engañoso. El concepto principal es distorsionar alguna información, pero esperamos que el autoencoder ignore inteligentemente esta pequeña anomalía y recree el original, es decir, recordemos lo que es importante e ignoremos las variantes innecesarias. Al repetir el entrenamiento muchas veces, el ruido de la información se cancelará entre sí y eventualmente se olvidará. Lo que queda son los patrones reales que nos importan.
En nuestra fotografía facial, seleccionamos puntos de cuadrícula de 5 × 5 y los desplazamos ligeramente de sus posiciones originales. Utilizamos un algoritmo simple para deformar la imagen de acuerdo a esos puntos de la cuadrícula desplazados. Incluso la imagen deformada puede no verse exactamente bien, pero ese es el ruido que queremos introducir. Luego usamos un algoritmo más complejo para construir una imagen de destino usando los puntos de cuadrícula cambiados. Queremos que nuestras imágenes creadas se vean tan cerca como las imágenes de destino.
 Parece extraño pero eso obliga al autocodificador a aprender las características más importantes.
Parece extraño pero eso obliga al autocodificador a aprender las características más importantes.
 Para manejar mejor las diferentes posturas, ángulos faciales y ubicaciones, también aplicamos el aumento de imagen para enriquecer los datos de entrenamiento. Durante el entrenamiento, rotamos, hacemos zoom, traducimos y volteamos nuestra imagen facial al azar dentro de un rango específico.
Para manejar mejor las diferentes posturas, ángulos faciales y ubicaciones, también aplicamos el aumento de imagen para enriquecer los datos de entrenamiento. Durante el entrenamiento, rotamos, hacemos zoom, traducimos y volteamos nuestra imagen facial al azar dentro de un rango específico.
Deep network model
El codificador se compone de 5 capas de convolución (convolution layers) para extraer características seguidas de 2 capas de dencidad (dense layers). Luego utiliza una capa de convolución para tomar muestras de la imagen. El decodificador continúa el muestreo (Upsampling) con 4 capas de convolución más hasta que reconstruye la imagen de 64 × 64.

Para aumentar la dimensión espacial, digamos de 16 × 16 a 32 × 32, utilizamos un filtro de convolución (un filtro de 3 × 3 × 256 × 512) para mapear la capa (16, 16, 256) en (16, 16, 512). Luego lo reformamos a (32, 32, 32, 128).
Unos cuantos problemas…
No te emociones demasiado. Si usas una mala implementación, una mala configuración o tu modelo no está bien entrenado, obtendrás el resultado del siguiente video… (Mira los primeros segundos. Ya he marcado el video alrededor de las 3:37.)
El área facial está parpadeando, borrosa y de color muy raro. Y hay cajas obvias alrededor de la cara. Parece que la gente le pega fotos en la cara por la fuerza bruta. Estos problemas se entienden fácilmente si explicamos cómo cambiar la cara manualmente.
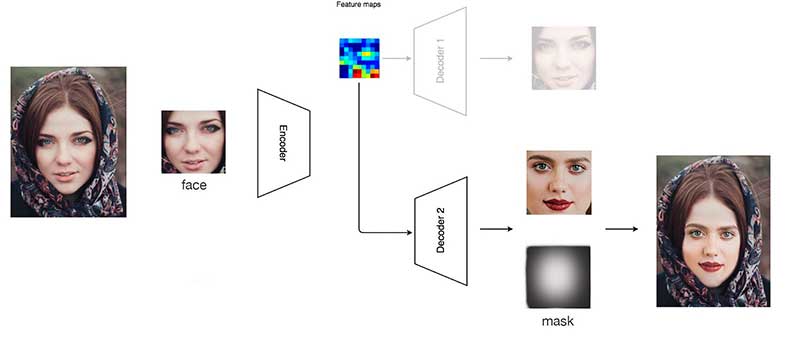
Empezamos con dos fotos (1 y 2) para dos mujeres. En la imagen 4, intentamos pegar la cara 1 sobre 2. Nos damos cuenta de que su cara es muy diferente y que el recorte de la cara (el rectángulo rojo) es demasiado grande. Parece que alguien le puso una máscara de papel. Ahora, intentemos pegar la cara 2 en la 1. En la imagen 3, usamos un recorte más pequeño. Creamos una máscara que elimina algunas de las áreas de las esquinas para que el recorte se pueda mezclar mejor. No es grandioso pero definitivamente mejor que 4. Pero hay un cambio repentino en el tono de la piel alrededor del área del límite. En la imagen 5, reducimos la opacidad de la máscara alrededor del límite para que la cara creada pueda mezclarse mejor. Pero el tono de color y el brillo del recorte aún no coinciden con el objetivo. Así que en la imagen 6, ajustamos el tono de color y el brillo del recorte para que coincida con nuestro objetivo. No es lo suficientemente bueno todavía, pero no es malo para nuestro pequeño esfuerzo.
 En Deepfakes, se crea una máscara en la cara creada para que pueda mezclarse con el vídeo de destino. para mejorara el efecto, podemos:
En Deepfakes, se crea una máscara en la cara creada para que pueda mezclarse con el vídeo de destino. para mejorara el efecto, podemos:
- Aplicar un filtro gaussiano para difuminar aún más el área del límite de la máscara,
- Configurar la aplicación para que expanda o contraiga aún más la máscara, o
- Controlar la forma de la máscara.
 Si miras más de cerca un video falso, puedes notar doble mentón o bordes fantasmas alrededor de la cara. Ese es el efecto secundario de fusionar 2 imágenes usando una máscara. En particular, la mayoría de los videos falsos que se ven, la cara es un poco enterrada en comparación con otras partes de la imagen. Para contrarrestarlo, podemos configurar Deepfakes para que aplique un filtro de nitidez a la cara creada antes de la mezcla. Este es un proceso de prueba y error para encontrar el equilibrio correcto entre los artefactos y la nitidez. Obviamente, la mayoría de las veces, necesitamos crear imágenes ligeramente borrosas para eliminar los artefactos notorios.
Si miras más de cerca un video falso, puedes notar doble mentón o bordes fantasmas alrededor de la cara. Ese es el efecto secundario de fusionar 2 imágenes usando una máscara. En particular, la mayoría de los videos falsos que se ven, la cara es un poco enterrada en comparación con otras partes de la imagen. Para contrarrestarlo, podemos configurar Deepfakes para que aplique un filtro de nitidez a la cara creada antes de la mezcla. Este es un proceso de prueba y error para encontrar el equilibrio correcto entre los artefactos y la nitidez. Obviamente, la mayoría de las veces, necesitamos crear imágenes ligeramente borrosas para eliminar los artefactos notorios.
Incluso el autoencoder debería crear caras que coincidan con el tono del color de destino, a veces necesita ayuda. Deepfakes proporciona un post-procesamiento para ajustar el tono de color, el contraste y el brillo de la cara creada para que coincida con el vídeo de destino. También podemos aplicar la clonación sin fisuras de cv2 para mezclar la imagen creada con la imagen de destino mediante el ajuste automático del tono. Sin embargo, algunos de estos esfuerzos pueden ser contraproducentes. Podemos hacer que un marco en particular se vea genial. Pero si nos excedemos, puede dañar la suavidad temporal de los cuadros. De hecho, el clon sin fisuras en Deepfakes es una de las principales causas posibles de parpadeo.
Otra fuente importante de parpadeo es que el autoencoder no crea las caras adecuadas. Para ello, necesitamos añadir imágenes más diversificadas para entrenar mejor el modelo o aumentar el aumento de datos. Eventualmente, es posible que necesitemos entrenar el modelo por más tiempo. En los casos en los que no podemos crear la cara adecuada para algunos fotogramas de vídeo, omitimos los fotogramas problemáticos y utilizamos la interpolación para recrear los fotogramas eliminados.
Landmarks
También podemos deformar nuestra cara creada de acuerdo con los puntos de referencia de la cara en el marco de objetivo original.
 Así es como Rogue One transforma la cara de la joven princesa Leia en la de otra actriz.
Así es como Rogue One transforma la cara de la joven princesa Leia en la de otra actriz.

Mejorando la máscara
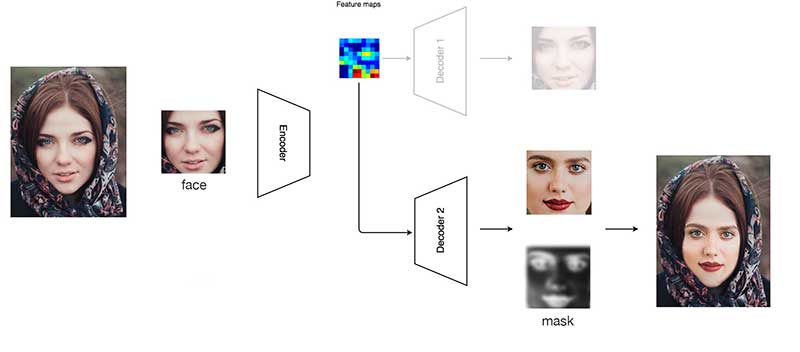
En nuestro esfuerzo anterior, nuestra máscara está preconfigurada. Podemos hacer un trabajo mucho mejor si nuestra máscara está relacionada con la imagen de entrada y la cara creada.
 es momenta de empezar a hablar de las Redes Adversarias Generativas (GAN).
es momenta de empezar a hablar de las Redes Adversarias Generativas (GAN).
GAN (Generative Adversary Networks)
En GAN, introducimos un discriminador de red profundo (un clasificador CNN) para distinguir si las imágenes faciales son originales o creadas por el ordenador. Cuando alimentamos imágenes reales a este discriminador, entrenamos al propio discriminador para que reconozca mejor las imágenes reales. Cuando introducimos imágenes creadas en el discriminador, lo usamos para entrenar a nuestro autoencoder para crear imágenes más realistas. Convertimos esto en una carrera en la que finalmente las imágenes creadas no se distinguen de las reales.
Además, nuestro decodificador genera imágenes y máscaras. Dado que estas máscaras se aprenden a partir de los datos de entrenamiento, pueden enmascarar mejor la imagen y crear una transición más suave a la imagen de destino. Además, maneja mejor las caras parcialmente obstruidas. En los vídeos falsos, cuando la cara está parcialmente bloqueada por una mano, el vídeo puede parpadear o enterrarse. Con una mejor máscara, podemos enmascarar el área obstruida en la cara creada y utilizar la parte de la imagen de destino en su lugar.
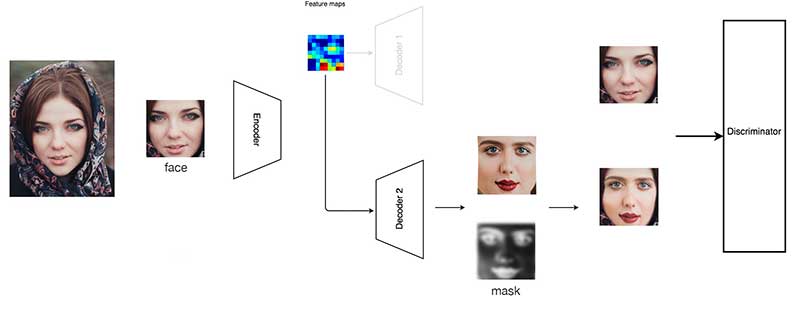 Aunque el GAN es potente, su formación lleva mucho tiempo y requiere un mayor nivel de conocimientos técnicos para corregirla. Por lo tanto, no es tan popular como debería ser.
Aunque el GAN es potente, su formación lleva mucho tiempo y requiere un mayor nivel de conocimientos técnicos para corregirla. Por lo tanto, no es tan popular como debería ser.
Función de pérdida
Además del coste de reconstrucción, GAN añade un coste de generador y discriminador para la formación del modelo. De hecho, podemos añadir funciones de pérdida adicionales para perfeccionar nuestro modelo. Una de las más comunes es el coste de los bordes, que mide si la imagen de destino y la imagen creada tienen el mismo borde en la misma ubicación. Algunas personas también miran la pérdida perceptiva. El costo de la reconstrucción mide la diferencia de píxeles entre la imagen de destino y la imagen creada. Sin embargo, puede que no sea una buena medida para medir cómo perciben los objetos nuestros cerebros. Por lo tanto, algunas personas pueden utilizar la pérdida de percepción para reemplazar la pérdida de reconstrucción original.
Demostración
Vamos a ver algunos buenos videos de Deepfakes y ver si podemos detectarlos ahora. Los deberiamos reproducir en cámara lenta y prestar especial atención a:
- ¿Es demasiado borroso en comparación con otras áreas no faciales del vídeo?
- ¿Parpadea?
- ¿Tiene un cambio de tono de piel cerca del borde de la cara?
- ¿Tiene doble mentón, doble ceja, doble borde en la cara?
- Cuando la cara está parcialmente bloqueada por las manos u otras cosas, ¿parpadea o se vuelve borrosa?
En la realización de videos falsos, aplicamos diferentes funciones de pérdida para hacer videos visualmente más agradables. Como se muestra en las fotos falsas de Trump, los rasgos de su rostro se parecen mucho al real, pero cambia si se mira más de cerca. Por lo tanto, en mi opinión, si introducimos el vídeo de destino en un clasificador para su identificación, es muy probable que falle. Además, podemos escribir programas para verificar la suavidad temporal. Dado que creamos caras de forma independiente a través de fotogramas, debemos esperar que la transición sea menos fluida en comparación con un vídeo real.
Sincronización labial desde un audio
El vídeo realizado por Jordan Peele es uno de los más difíciles de identificar como falso. Pero una vez que se mira más de cerca, el labio inferior de Obama es más borroso en comparación con otras partes de la cara. Por lo tanto, en lugar de cambiar la cara, sospecho que se trata de un vídeo real de Obama, pero la boca está fabricada para sincronizar los labios con audio falso.
Para el resto de esta sección, discutiremos la tecnología de sincronización labial realizada en la Universidad de Washington (UW). A continuación se muestra el flujo de trabajo del papel de sincronización labial. Sustituye el audio de un discurso presidencial semanal por otro audio (audio de entrada). En el proceso, volvemos a sintetizar la boca y el área de la barbilla para que su movimiento esté sincronizado con el audio falso.
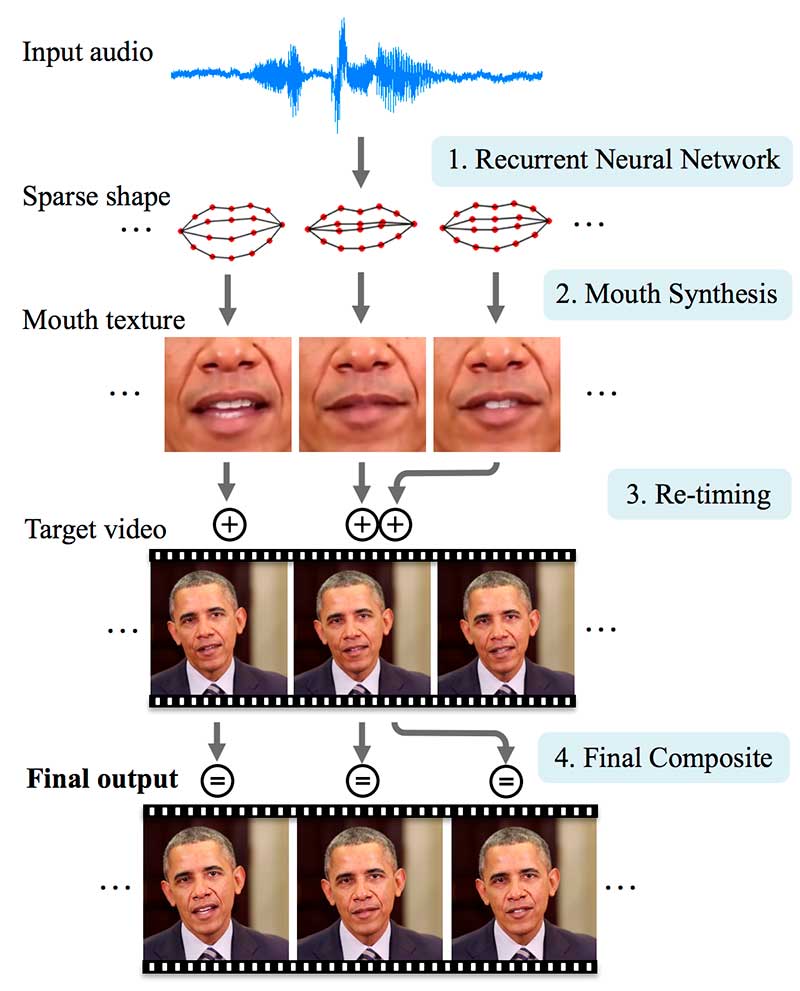 Primero, usando una red LSTM, el audio ‘x’ se transforma en una secuencia de 18 puntos de referencia ‘y’ en el labio. Este LSTM produce una forma de boca dispersa para cada fotograma de salida de vídeo.
Primero, usando una red LSTM, el audio ‘x’ se transforma en una secuencia de 18 puntos de referencia ‘y’ en el labio. Este LSTM produce una forma de boca dispersa para cada fotograma de salida de vídeo.
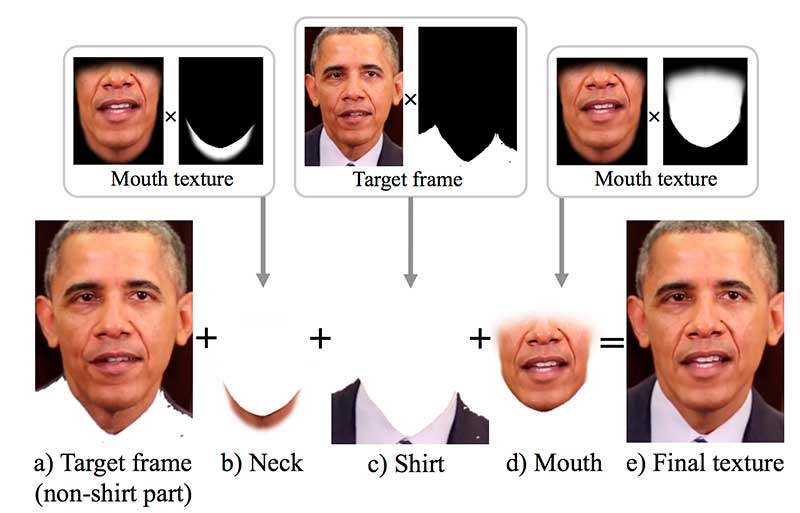
 Dada la forma de la boca ‘y’, sintetiza la textura de la boca para la boca y el área de la barbilla. Estas texturas de boca se componen con el vídeo de destino para recrear el cuadro de destino:
Dada la forma de la boca ‘y’, sintetiza la textura de la boca para la boca y el área de la barbilla. Estas texturas de boca se componen con el vídeo de destino para recrear el cuadro de destino:
 Entonces, ¿cómo creamos la textura de la boca? Queremos que parezca real pero también que tenga una suavidad temporal. Por lo tanto, la aplicación revisa los vídeos de destino para buscar los fotogramas de los candidatos que tengan la misma forma de boca calculada que la que queremos. Luego fusionamos los candidatos usando una función mediana. Como se muestra a continuación, si utilizamos más cuadros candidatos para hacer el promedio, la imagen se vuelve borrosa mientras que la suavidad temporal mejora (sin parpadear). Por otro lado, la imagen puede estar menos enterrada, pero podemos ver que parpadea al pasar de un fotograma a otro.
Entonces, ¿cómo creamos la textura de la boca? Queremos que parezca real pero también que tenga una suavidad temporal. Por lo tanto, la aplicación revisa los vídeos de destino para buscar los fotogramas de los candidatos que tengan la misma forma de boca calculada que la que queremos. Luego fusionamos los candidatos usando una función mediana. Como se muestra a continuación, si utilizamos más cuadros candidatos para hacer el promedio, la imagen se vuelve borrosa mientras que la suavidad temporal mejora (sin parpadear). Por otro lado, la imagen puede estar menos enterrada, pero podemos ver que parpadea al pasar de un fotograma a otro.
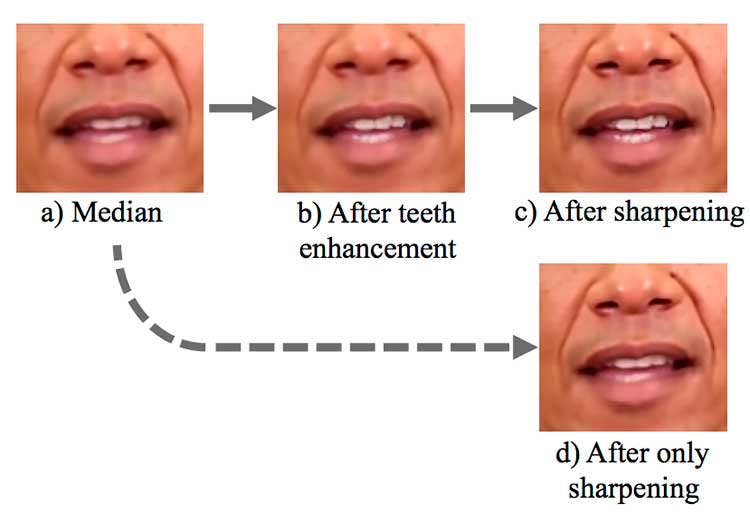
 Para compensar lo borroso de la imagen, se realiza un realce y afilado de los dientes. Pero obviamente, la nitidez no puede ser completamente restaurada para el labio inferior.
Para compensar lo borroso de la imagen, se realiza un realce y afilado de los dientes. Pero obviamente, la nitidez no puede ser completamente restaurada para el labio inferior.
 Finalmente, necesitamos retemporizar el marco para saber dónde insertar la textura falsa de la boca. Esto nos ayuda a sincronizarnos con el movimiento de la cabeza. En particular, la cabeza de Obama suele dejar de moverse cuando hace una pausa en su discurso.
Finalmente, necesitamos retemporizar el marco para saber dónde insertar la textura falsa de la boca. Esto nos ayuda a sincronizarnos con el movimiento de la cabeza. En particular, la cabeza de Obama suele dejar de moverse cuando hace una pausa en su discurso.
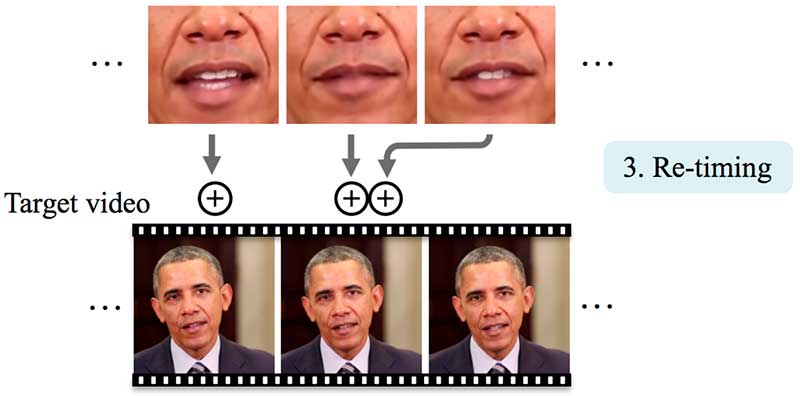 La fila superior de abajo es la de los fotogramas de vídeo originales para el audio de entrada que utilizamos. Insertamos este audio de entrada en nuestro vídeo de destino (la segunda fila). Cuando lo comparamos lado a lado, nos damos cuenta de que el movimiento de la boca a partir del vídeo original es muy parecido al movimiento de la boca fabricada.
La fila superior de abajo es la de los fotogramas de vídeo originales para el audio de entrada que utilizamos. Insertamos este audio de entrada en nuestro vídeo de destino (la segunda fila). Cuando lo comparamos lado a lado, nos damos cuenta de que el movimiento de la boca a partir del vídeo original es muy parecido al movimiento de la boca fabricada.
 UW utiliza marcos existentes para crear la textura de la boca. En su lugar, podemos usar el concepto de Deepfakes para generar la textura de la boca directamente desde el autoencoder. Necesitamos recopilar miles de fotogramas y usar el LSTM para extraer las características tanto del vídeo como del audio. Entonces podemos entrenar un decodificador para generar la textura de la boca.
UW utiliza marcos existentes para crear la textura de la boca. En su lugar, podemos usar el concepto de Deepfakes para generar la textura de la boca directamente desde el autoencoder. Necesitamos recopilar miles de fotogramas y usar el LSTM para extraer las características tanto del vídeo como del audio. Entonces podemos entrenar un decodificador para generar la textura de la boca.
Fuente: medium.com/@jonathan_hui/how-deep-learning-fakes-videos-deepfakes-and-how-to-detect-it-c0b50fbf7cb9










